- What is AI All About?
- What is AI – specifically what is deep learning? (and the internet of things – IoT)
- What is AI; Specifically What is Machine Learning?
- What is AI – the definitive guide

By VICTOR ANJOS
Artificial intelligence is the future. Artificial intelligence is science fiction. Artificial intelligence is already part of our everyday lives. All those statements are true, it just depends on what flavor of AI you are referring to.
Most of us are familiar with the term “Artificial Intelligence.” After all, it’s been a popular focus in movies such as The Terminator, The Matrix, and Ex Machina but you may have recently been hearing about other terms like “Machine Learning” and “Deep Learning,” sometimes used interchangeably with artificial intelligence. As a result, the difference between artificial intelligence, machine learning, and deep learning can be very unclear.
I’ll begin by giving a quick explanation of what Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) actually mean and how they’re different this week (over a many part series) and explain some of their applications and current best practices, paradigms and uses.
What is Machine Learning (ML)?
Machine learning is a subset of AI. That is, all machine learning counts as AI, but not all AI counts as machine learning. For example, symbolic logic – rules engines, expert systems and knowledge graphs – could all be described as AI, and none of them are machine learning.
One aspect that separates machine learning from the knowledge graphs and expert systems is its ability to modify itself when exposed to more data; i.e. machine learning is dynamic and does not require human intervention to make certain changes. That makes it less brittle, and less reliant on human experts.
In 1959, Arthur Samuel, one of the pioneers of machine learning, defined machine learning as
That is, machine-learning programs have not been explicitly entered into a computer, like the if-then statements of other programs. Machine-learning programs, in a sense, adjust themselves in response to the data they’re exposed to.
Are they actually learning?
The “learning” part of machine learning means that ML algorithms attempt to optimize along a certain dimension; i.e. they usually try to minimize error or maximize the likelihood of their predictions being true. This has three names: an error function, a loss function, or an objective function, because the algorithm has an objective.
When someone says they are working with a machine-learning algorithm, you can get to the gist of its value by asking
How does one minimize error? Well, one way is to build a framework that multiplies inputs in order to make guesses as to the inputs’ nature. Different outputs/guesses are the product of the inputs and the algorithm. Usually, the initial guesses are quite wrong, and if you are lucky enough to have ground-truth labels pertaining to the input, you can measure how wrong your guesses are by contrasting them with the truth, and then use that error to modify your algorithm.
That’s what neural networks do. They keep on measuring the error and modifying their parameters until they can’t achieve any less error. They are, in short, an optimization algorithm. If you tune them right, they minimize their error by guessing and guessing and guessing again.
Where do the examples come from?
Most of the current applications of the machine learning leverage supervised learning.
In this approach #machines are shown thousands or millions of examples and trained how to correctly solve a problem. For example, using historical fraud data we can train an algorithm to identify a fraudulent from non-fraudulent activity. Once the machine learns how to correctly classify the cases, we deploy the model for future usage.
Supervised, unsupervised and reinforced learning
Other usage of ML can be broadly classified between unsupervised learning and reinforced learning.
In unsupervised learning, there is no label or output which is used to train the machine, however machine is trained to identify hidden patterns or segments.
Reinforced learning on the other hand focuses on a constantly learning system which incentivizes an algorithm for meeting the final goals under the given constraints.
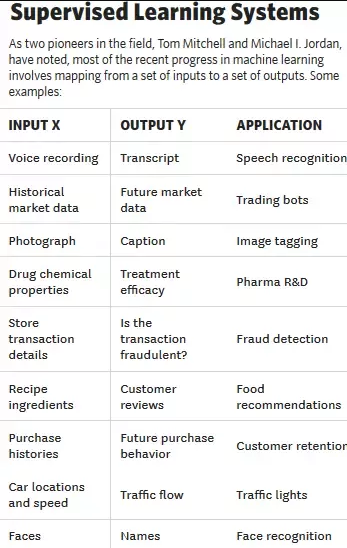
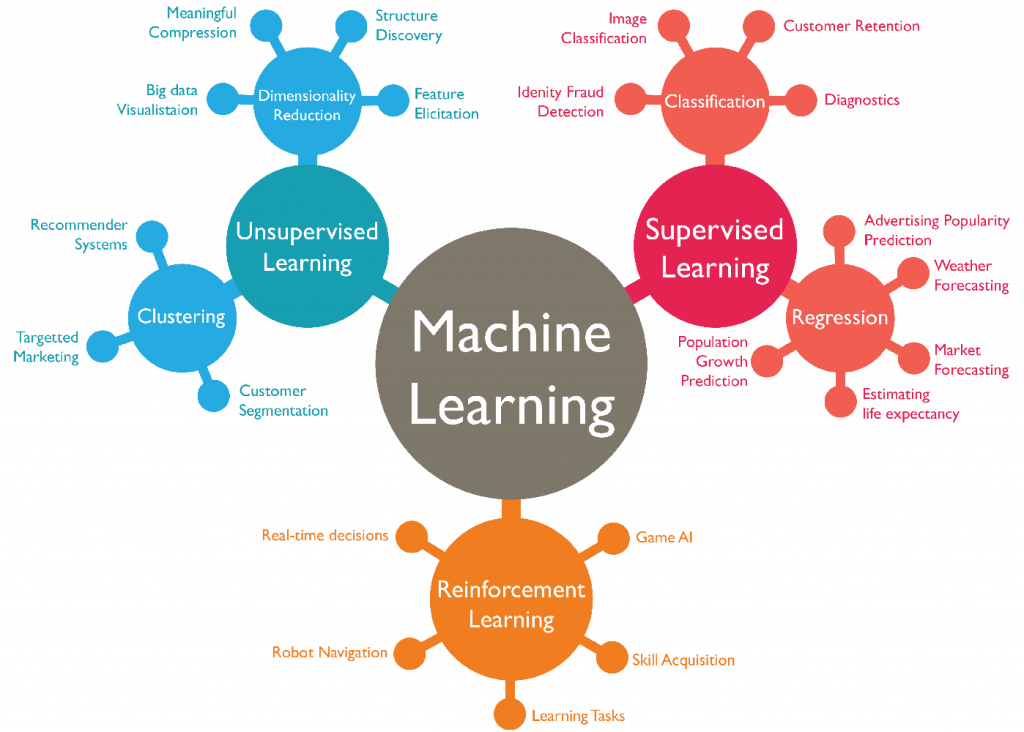
Specific types of Machine Learning
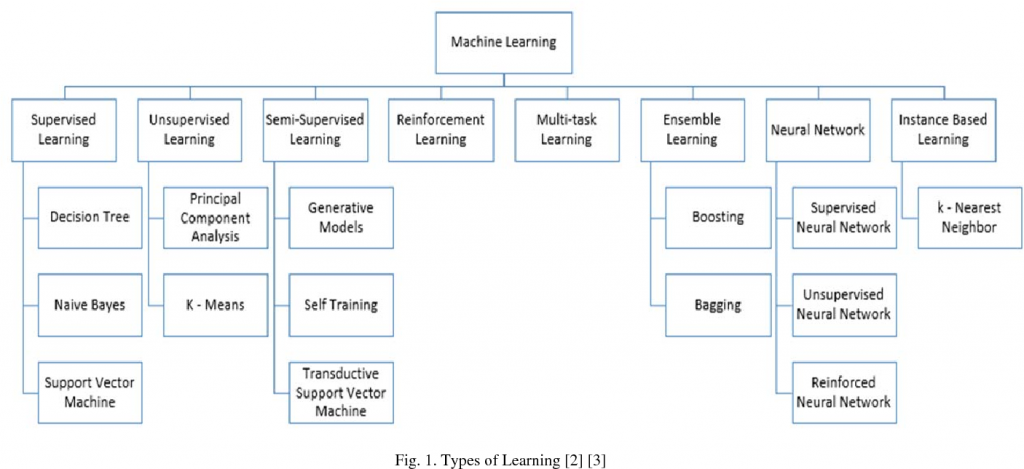
To finish this assignment, an extensive variety of algorithms have been developed such as Linear Regression, Logistic Regression, Support Vector Machines (SVM), K-Means, Decision Trees, Random Forests, Naive Bayes, PCA and lastly, Artificial Neural Networks (ANN), etc…
Linear regression
Linear regression is a linear system and the coefficients can be calculated analytically using linear algebra. … Linear regression does provide a useful exercise for learning stochastic gradient descent which is an important algorithm used for minimizing cost functions by machine learning algorithms.
Logistic Regression
Logistic regression is another technique borrowed by machine learning from the field of statistics. It is the go-to method for binary classification problems (problems with two class values). … Techniques used to learn the coefficients of a logistic regression model from data.
Decision Tree
Decision tree learning uses a decision tree (as a predictive model) to go from observations about an item (represented in the branches) to conclusions about the item’s target value (represented in the leaves). It is one of the predictive modelling approaches used in statistics, data mining and machine learning.
Clustering Algorithms
Clustering is a method of unsupervised learning and a common technique for statistical data analysis used in many fields. K-means clustering is an algorithm to classify or to group your objects based on attributes/features into K number of the group. K is a positive integer number.
Naive Bayes
In machine learning, naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes’ theorem with strong (naive) independence assumptions between the features. Naive Bayes has been studied extensively since the 1950s.
Ensemble Methods
Stacking Multiple Machine Learning Models. Stacking, also known as stacked generalization, is an ensemble method where the models are combined using another machine learning algorithm. … Then this new dataset is used as input for the combiner machine learning algorithm.
Independent Component Analysis
Independent component analysis attempts to decompose a multivariate signal into independent non-Gaussian signals. As an example, the sound is usually a signal that is composed of the numerical addition, at each time t, of signals from several sources. The question then is whether it is possible to separate these contributing sources from the observed total signal. When the statistical independence assumption is correct, blind ICA separation of a mixed signal gives very good results.It is also used for signals that are not supposed to be generated by a mixing for analysis purposes.
A simple application of ICA is the “cocktail party problem”, where the underlying speech signals are separated from a sample data consisting of people talking simultaneously in a room. Usually, the problem is simplified by assuming no time delays or echoes.
Principal Component Analysis (PCA)
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components (or sometimes, principal modes of variation).
Random Forest
Random forests or random decision forests are an ensemble learning method for classification, regression, and other tasks, that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random decision forests correct for decision trees’ habit of over-fitting to their training set.
SVM (Support Vector Machine)
In machine learning, support vector machines (SVMs, also support vector networks) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis.
K-Means
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining.
KNN (K- Nearest Neighbors)
k-nearest neighbors algorithm. In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space.
At its core, machine learning is simply a way of achieving AI
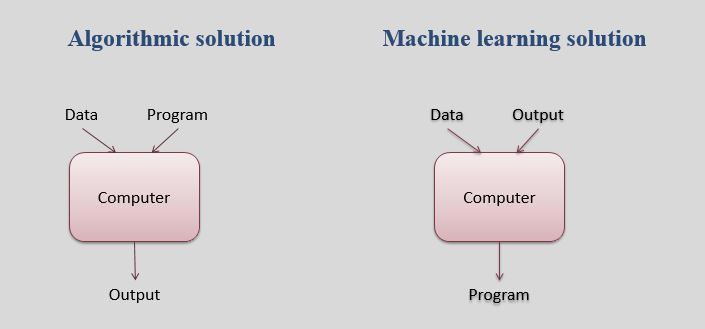
Arthur Samuel coined the phrase not too long after AI, in 1959, defining it as
You can get AI without using machine learning, but this would require building millions of lines of codes with complex rules and decision-trees. So instead of hard coding software routines with specific instructions to accomplish a particular task, machine learning is a way of “training” an algorithm so that it can learn how. “Training” involves feeding huge amounts of data to the algorithm and allowing the algorithm to adjust itself and improve.
Machine Learning is built based on algorithmic approaches that over the years included decision tree learning, inductive logic programming, clustering, reinforcement learning, and Bayesian networks among others. But only the developments in the area of neural networks, which are designed to work by classifying information in the same way a human brain does, allowed for greater (recent) breakthroughs.
Although Artificial Neural Networks have been around for a long time, only in the last few years the computing power and the ability to use vector processing from GPUs enabled building networks with much larger and deeper layers than it was previously possible and it brought amazing results. Although there is no clear border between the terms, that area of Machine Learning is often described as Deep Learning.
This is what we’ll discuss in the next article, coming in a few days.
So what do you do when all signs point to having to go to University to gain any sort of advantage? Unfortunately it’s the current state of affairs that most employers will not hire you unless you have a degree for even junior or starting jobs. Once you have that degree, coming to my Mentor Program, with 1000ml with our Patent Pending training system, the only such system in the world; is the only way to gain the practical knowledge and experience that will jump start your career.
Check out our next dates below for our upcoming seminars, labs and programs, we’d love to have you there.