By VICTOR ANJOS
Overview of AI-based Legal Clauses Partitioning and Classification
AI Legal Clauses Classification is a process that can optimize your organization. Clause partitioning and classification is a critical task in the legal industry, which involves breaking down legal documents into individual clauses and categorizing them based on their content and purpose. With the rise of Artificial Intelligence (AI), the process of clause partitioning and classification has become more efficient and accurate.
Importance of Clause Partitioning and Classification in Legal Documents
Accurate clause partitioning and classification is crucial in the legal industry. It enables lawyers and legal teams to better understand the content of legal documents, identify key clauses, and make informed decisions. This process also helps organizations to manage and organize their legal document library more effectively.
Purpose of this Guide
The purpose of this guide is to provide a practical understanding of AI-based clause partitioning and classification. This guide will cover the basics of AI-based clause partitioning and classification, how to prepare data for AI-based clause partitioning and classification, how to build and train an AI model, and how to deploy and use the model

Understanding Clause Partitioning and Classification with AI
What is Legal Clauses Partitioning and Classification?
Clause partitioning is the process of breaking down legal documents into individual clauses. Classification, on the other hand, is the process of categorizing the clauses based on their content and purpose. AI-based clause partitioning and classification is the application of Artificial Intelligence to automate this process.
Benefits of Using AI for Clause Partitioning and Classification
The benefits of using AI for clause partitioning and classification are numerous. AI-based clause partitioning and classification enables organizations to:
• Save time and effort in manual document analysis
• Improve accuracy and consistency in clause partitioning and classification
• Automate document management and organization
• Enhance the overall efficiency of legal teams
How AI-based Clause Partitioning and Classification Works
AI-based clause partitioning and classification works by training a machine learning model with a large dataset of legal documents. The model is then able to identify the structure of legal documents and categorize the clauses based on their content and purpose. The process of AI-based clause partitioning and classification involves the following steps:
1. Data collection and preparation
2. Model development and training
3. Model deployment and integration
4. Monitoring and maintenance
Preparing Data for AI-based Clause Partitioning and Classification
Types of Legal Documents for Clause Partitioning and Classification
There are various types of legal documents that can be processed using AI-based clause partitioning and classification, including contracts, agreements, and legal memos.
Data Collection for Training, Validation, and Testing
The quality and quantity of data used for training, validation, and testing are crucial for the success of AI-based clause partitioning and classification. Legal teams can collect data from various sources, including existing legal document libraries and publicly available databases.
Preprocessing of Legal Documents
Once the data has been collected, it must be preprocessed to prepare it for training the AI model. This process involves cleaning and formatting the data, converting it into a suitable format for the AI model, and splitting it into training, validation, and testing datasets.
Quality Assurance of Data
Before starting the AI model training, it is crucial to ensure that the data collected for training and validation is of high quality. Poor quality data can lead to inaccurate results and hamper the performance of the AI model. The following are some best practices to ensure the quality of the data used for clause partitioning and classification:
Data Cleaning and Preprocessing
Data cleaning and preprocessing is the first step in ensuring data quality. This process involves removing any irrelevant or redundant information from the data, as well as formatting it so that it can be used for training the AI model. This could include removing duplicates, correcting errors, and converting the data into a standard format, such as CSV or JSON.
Data Annotation
Data annotation is the process of manually labeling the data to provide context and structure to the AI model. This is especially important in legal document analysis, as the meaning and context of clauses can be complex. The data annotator must have a thorough understanding of legal language and the document being annotated. Annotation should be performed by multiple annotators to ensure consistency and accuracy.
Splitting the Data into Train and Test Sets
Once the data is cleaned and annotated, it should be split into two separate sets: a training set and a test set. The training set is used to train the AI model, while the test set is used to evaluate the performance of the model. The ratio of the data split between the training and test sets will depend on the size of the data set, with a common ratio being 70/30 or 80/20.
Monitoring Data Quality
Monitoring the quality of the data used for training and validation is important to ensure that the AI model is being trained on accurate data. This could involve manual review of the data by legal experts, as well as the use of quality control tools to identify any inconsistencies or inaccuracies. Regular monitoring of data quality is essential to maintain the accuracy and performance of the AI model.
By following these best practices for quality assurance of data, you can ensure that your AI-based clause partitioning and classification model is trained on high quality data, leading to accurate and reliable results.
Building and Training the AI Model
Once the legal document data is collected, preprocessed, and quality assured, it’s time to build and train the AI model for clause partitioning and classification. Here are the steps to follow for this process:
Choosing the Right AI Model for Legal Clauses Partitioning and Classification
There are various AI models available for clause partitioning and classification, such as decision trees, random forests, neural networks, and more. It is important to choose the right model that best fits the requirements of your legal documents. A decision tree model is a good starting point for simple legal documents, while neural networks might be necessary for complex documents.
Setting up the Environment for Model Development
Once the right AI model is chosen, set up a development environment with the necessary tools and packages required to build and train the model. This can be done using popular machine learning platforms like TensorFlow, PyTorch, or scikit-learn.
Training the AI Model with Legal Documents Data
Once the environment is set up, start training the AI model with the preprocessed legal document data. This step requires the model to learn from the data and improve its performance over time. The model should be trained on multiple iterations until it reaches a satisfactory level of performance, based on metrics like accuracy, recall, and precision.
Evaluating Model Performance
After training the model, it’s important to evaluate its performance to ensure that it’s working as expected. Evaluate the model by running predictions on a separate test dataset and comparing the results with the actual output. Adjust the model parameters if necessary, and repeat the training and evaluation process until you achieve the desired level of performance.
Deploying the AI Model for Clause Partitioning and Classification
Once the AI model is trained and evaluated, it’s ready to be deployed in the production environment. Here are the steps to follow:
Deploying the Model in the Production Environment
Deploy the AI model in the production environment, and integrate it with the legal document management system. This allows the model to be used for clause partitioning and classification of real-world legal documents.
Integrating the Model with Legal Document Management System
Integrate the AI model with the legal document management system to automate the clause partitioning and classification process. This integration can be done using APIs or other integration tools available with the document management system.
Monitoring and Maintaining the Model
After deploying the model, it’s important to monitor its performance and make updates as necessary. This includes regularly retraining the model with updated legal document data, monitoring its accuracy, and updating the model parameters if necessary.
Conclusion
AI-based clause partitioning and classification is a powerful tool that can help lawyers and legal professionals analyze and classify legal documents with ease. With the right data, training, and development, it is possible to build an AI model that can accurately partition and classify legal documents.

VIII. References
A. List of Sources Cited in the Article
“Robotic Process Automation (RPA).” Gartner, Gartner, 18 Mar. 2020, www.gartner.com/en/information-technology/glossary/robotic-process-automation.
“The Benefits of Integrating Robotic Process Automation with AI.” Cognizant, 27 Oct. 2020, www.cognizant.com/whitepapers/the-benefits-of-integrating-robotic-process-automation-with-ai-codex2228.pdf.
“How AI and NLP Are Revolutionizing Customer Service.” Cognizant, 2 Apr. 2020, www.cognizant.com/insights/how-ai-and-nl
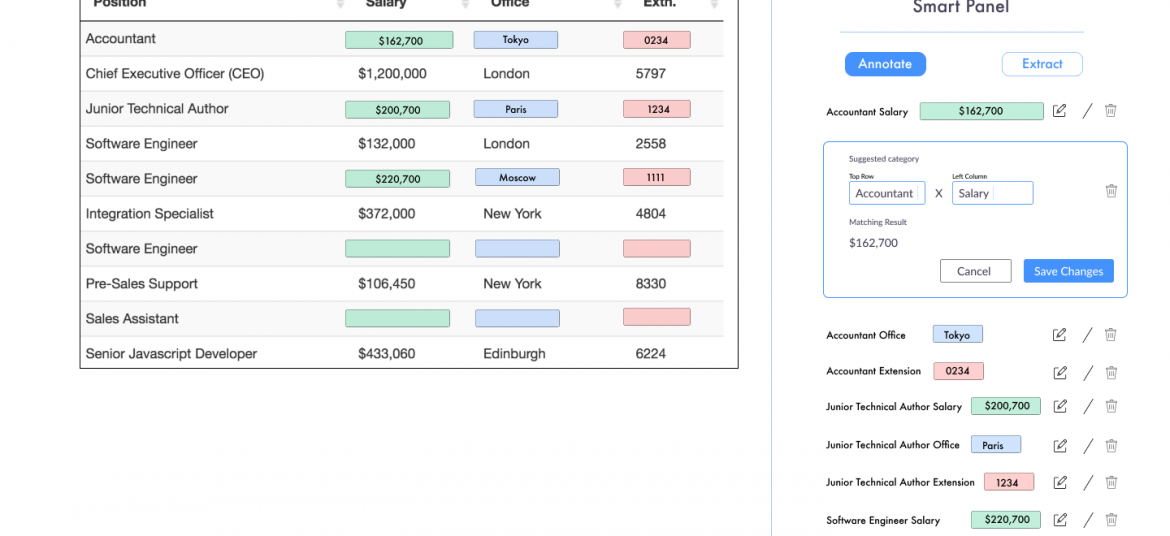

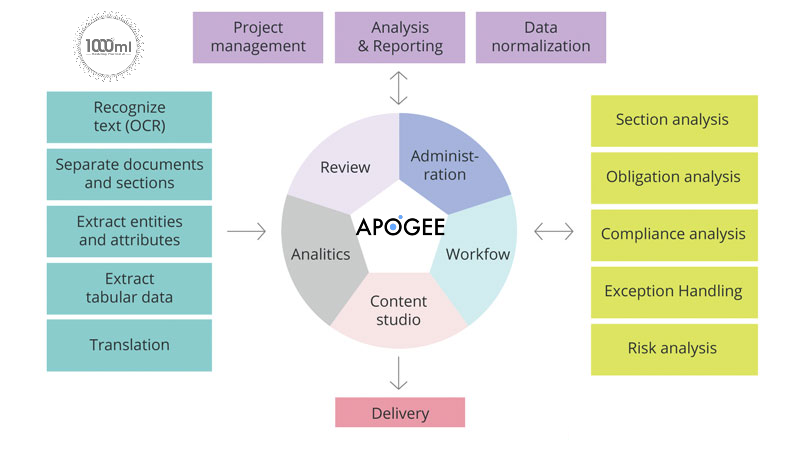
Apogee Suite of NLP and AI tools made by 1000ml has helped Small and Medium Businesses in several industries, large Enterprises and Government Ministries gain an understanding of the Intelligence that exists within their documents, contracts, and generally, any content.
Our toolset – Apogee, Zenith and Mensa work together to allow for:
- Any document, contract and/or content ingested and understood
- Document (Type) Classification
- Content Summarization
- Metadata (or text) Extraction
- Table (and embedded text) Extraction
- Conversational AI (chatbot)
Search, Javascript SDK and API
- Document Intelligence
- Intelligent Document Processing
- ERP NLP Data Augmentation
- Judicial Case Prediction Engine
- Digital Navigation AI
- No-configuration FAQ Bots
- and many more
Check out our next webinar dates below to find out how 1000ml’s tool works with your organization’s systems to create opportunities for Robotic Process Automation (RPA) and automatic, self-learning data pipelines.