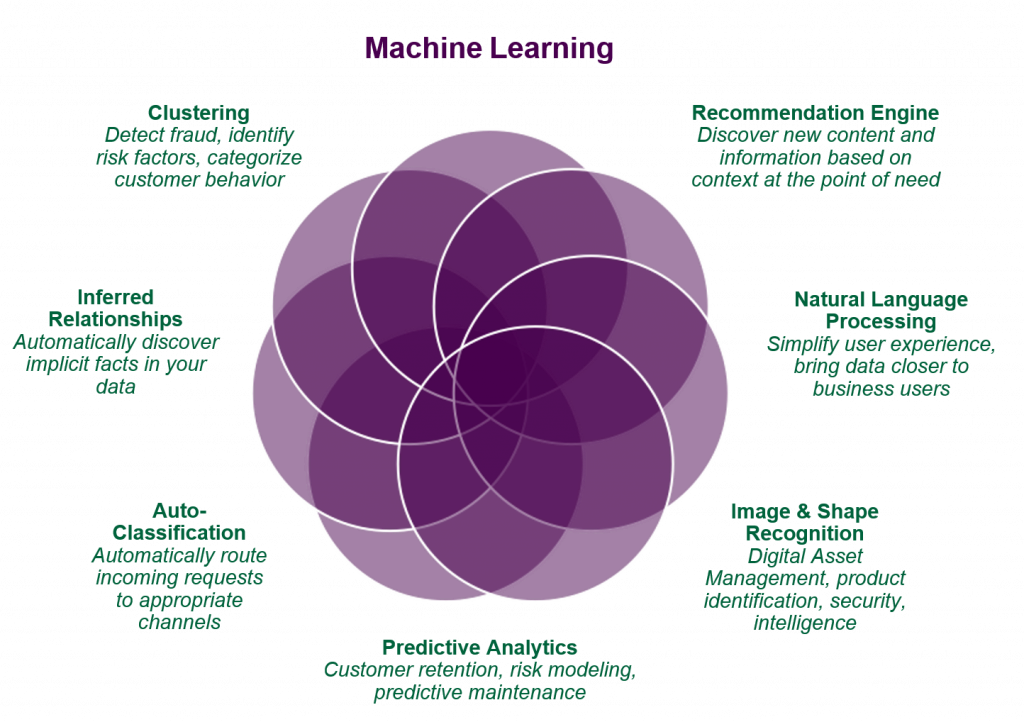
What about Finance? Legal? Operations?
Enter NLP, Intelligence Document Processing (IDP) and Document AI.
Document AI
The industry has evolved from OCR to solutions that use multiple AI technologies to address the bottlenecks. These solutions are categorized by:
- The old-school approach: OCR
- The modern approach: Various names, including:
- Intelligent Data Processing
- Intelligent Data Capture
- Machine Learning OCR
- Cognitive Capture
- AI OCR
- AI RPA
Elsewhere you will read how AI technology is being applied to solve unstructured data problems. Be cautious here; AI has become a buzzword some vendors deploy to cloud the waters when it comes to describing how AI plays in their solutions.
For now, the key point is this:
Intelligent Document Processing (IDP) can extract virtually all the information, understand the data, and create additional value from complex documents.

Three common problems Apogee’s Document AI can solve for you right now
1000ml has worked hand-in-hand with enterprises and companies to solve complex data problems. We have lots of stories to share. For now, let’s review the top three use cases we encounter most often.
Data Extraction From Annual Reports

Data Extraction From Technical Drawings

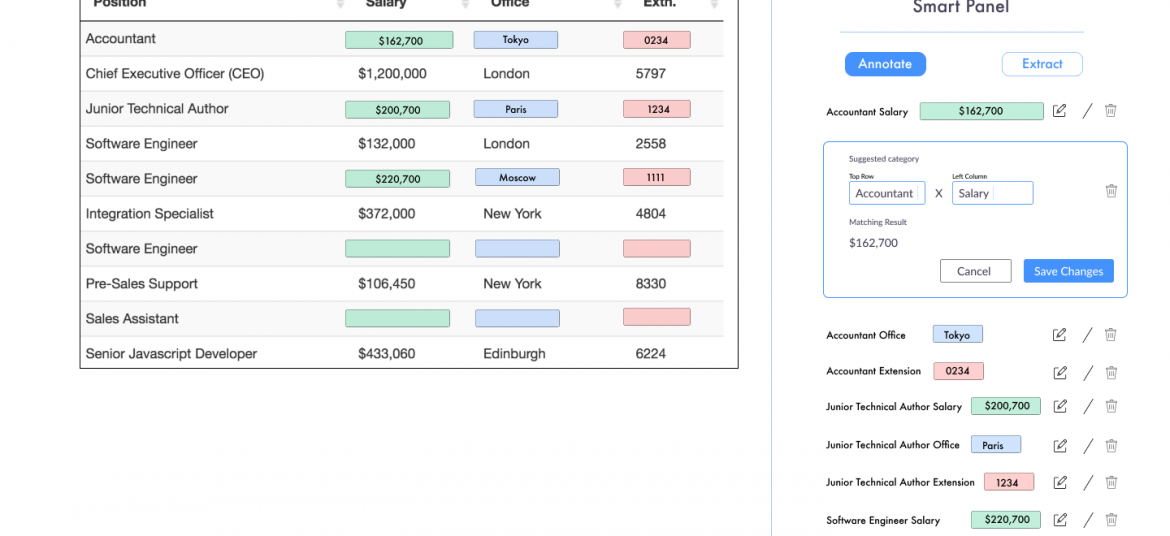
Data Extraction From Tables