- The 6 crucial skills Jr Data Scientists need – Part 2
- The 6 crucial skills Jr Data Scientists need

By VICTOR ANJOS
I speak and write a lot about broken education systems and learning in general and give my readers just a little insight into what to do about it. Well, if you’re an aspiring Data Scientist (or Data Science Analyst), then this post is all about you and the plight of getting your foot in the door.
Obviously, the easiest way to gain these skills is to come to one of our upcoming intro sessions and join in a upcoming cohort. We are still the only Mentor program which has a recruitment (or actually placement) function. It is similar to how executive search works, except this part of our business is exclusively for entry level data candidates.
So you want to be a Data Scientist
So what is it that entry level candidates really need? It’s actually rather simple when you think of the entire life-cycle of a data science or machine learning project you would undertake. Let’s quickly walk through those steps and talk about the necessary skills to excel at this, and ultimately, get hired.
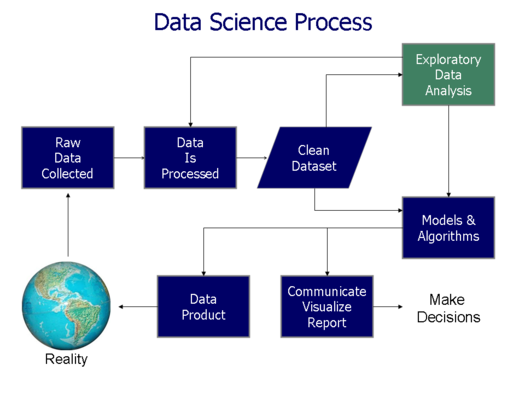
Starting a Project
Someone finds you, and asks you to do some “data science” or analysis because they know that you’re capable. You’re in the stage of Problem Discovery now and it’s time to hunker down, it’s about to get real!
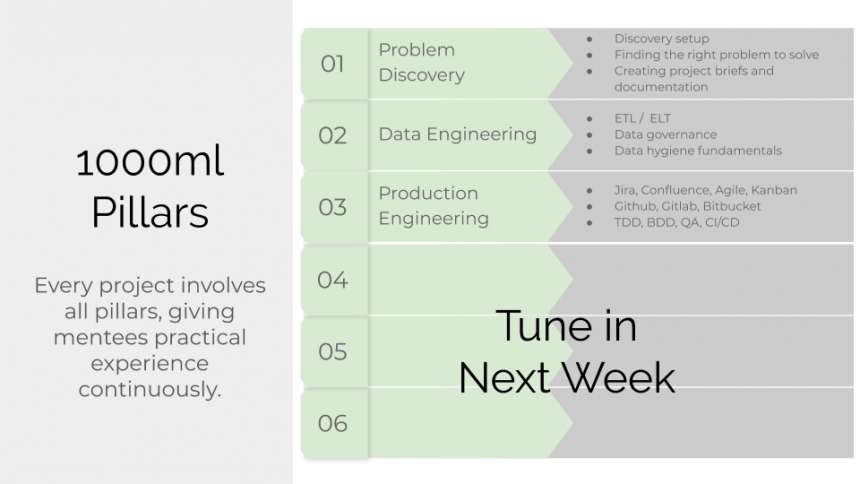
Problem Discovery

Ok, good – problem defined and we’re ready to work on some data. Let’s get that data in my Jupyter notebook ASAP.
Data Engineering and Hygiene
-
-
Dealing with missing data
-
Standardizing the process
-
Validating data accuracy
-
Removing duplicate data
-
Handling structural errors
-
Getting rid of unwanted observations
-
As part of a good product organization, you will need to fit into their feature development practices, but that’s kinda weird and awkward for a typical Data Scientist right? You sort of want to live in a notebook and have all this piping and infrastructure just there, shouldn’t it be that easy?
Production Engineering
Code is not written in isolation, it is written collaboratively
If it’s not in version control, it doesn’t exist
Make the safe play as much as possible with architecture
Dangling code and poorly written code is the worst
Model Training is for others, not for you, silly
1. Give ways to others to train against your original data (version your data and give its URL, for example!)2. Give ways to others to evaluate against your test data
Don’t copy & paste, steal (but give credit)
No one uses Python2 (if they have a choice)
Tune in next week for the remaining pillars!
So what do you do when all signs point to having to go to University to gain any sort of advantage? Unfortunately it’s the current state of affairs that most employers will not hire you unless you have a degree for even junior or starting jobs. Once you have that degree, coming to a Finishing and Mentor Program, with 1000ml being the only one worldwide, is the only way forward to gaining the practical knowledge and experience that will jump start your career.
Check out our next dates below for our upcoming seminars, labs and programs, we’d love to have you there.