- The 6 crucial skills Jr Data Scientists need – Part 2
- The 6 crucial skills Jr Data Scientists need

By VICTOR ANJOS
I speak and write a lot about broken education systems and learning in general and give my readers just a little insight into what to do about it. Well, if you’re an aspiring Data Scientist (or Data Science Analyst), then this post is all about you and the plight of getting your foot in the door.
Obviously, the easiest way to gain these skills is to come to one of our upcoming intro sessions and join in a upcoming cohort. We are still the only Mentor program which has a recruitment (or actually placement) function. It is similar to how executive search works, except this part of our business is exclusively for entry level data candidates.
So you want to be a Data Scientist (Part 2)
We dive right back into the question of “What do I really need as an entry level candidate in the data science field?” in this 2-part series on the crucial skills necessary to get started on the right foot in your career.
If you missed the first part, you can find it here in which we talked about the need for data science candidates to ensure they are adept (and demonstrably so) at:
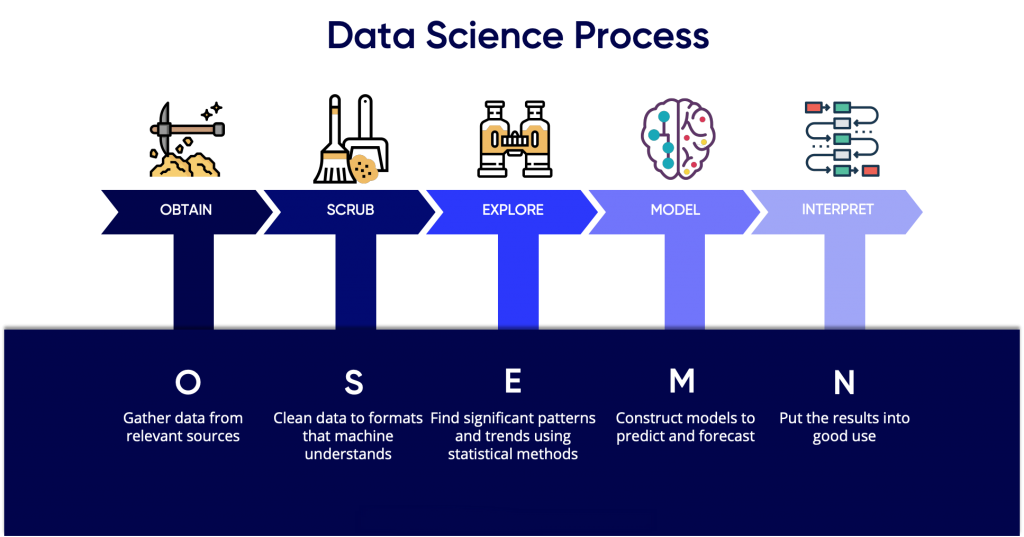
Starting use the Acquired (and, now clean) data
So now we gotten to a place where the data we have is sitting in the right places, whether that be on your local machine, some file storage service or in a database, and you have it sanitized, cleaned and ready for your exploratory, machine learning or deep learning methods.
So what now?
Analysis (or Modeling)
This is generally seen as the “SEXY” part of Data Science or machine learning. It is generally where all the MOOCs, online courses, bootcamps and tutorials online focus. It’s sort of the bench press of a data science project; it’s the part that everyone seems to always focus on, believing that if you model well, you’ll be a good data scientist. Unfortunately, that’s not the whole truth and literally only a sliver of the work required, as you can see from the lengthy series of posts.
Let’s briefly discuss modeling and what it entails, but literally, just briefly, as this topic is the most over-saturated part of data science, ML and AI. Once you have cleaned the data, you have to understand the information contained within at a high level. What kinds of obvious trends or correlations do you see in the data? What are the high-level characteristics and are any of them more significant than others?
Lastly, you will need to perform in-depth analysis (machine learning, statistical models, algorithms). As mentioned above, this step is usually the meat of your project,where you apply all the cutting-edge machinery of data analysis to unearth high-value insights and predictions.
Modeling (specifically)
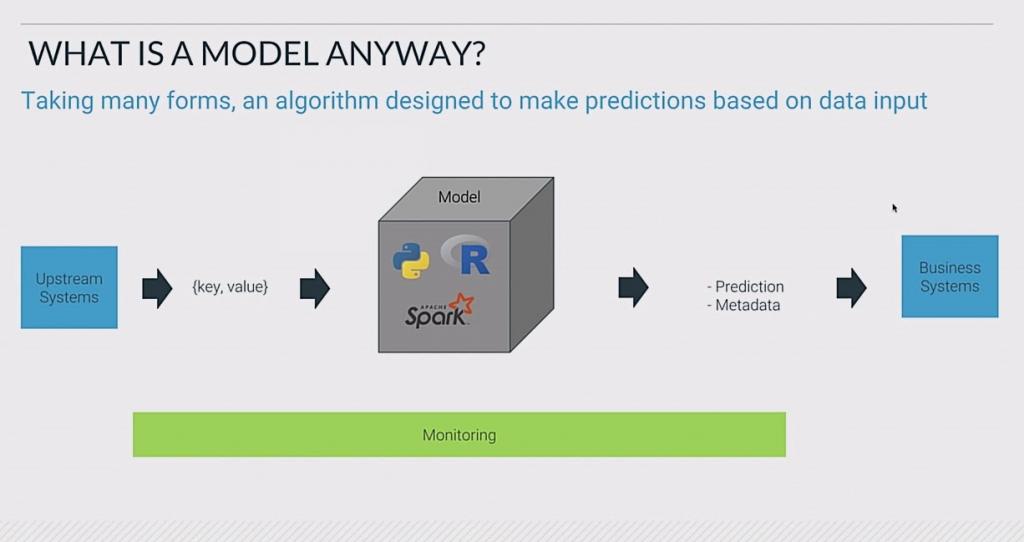
You’ve just modeled something in the real world! But is it a good model? Is it what you want to present? Hmmm… what next?
Experimentation and Model Performance
- Regression problems use certain evaluation metrics such as mean squared error (MSE)
- Classification problems use evaluation metrics as precision, accuracy and recall.
Setting an Evaluation Protocol
Maintaining a Hold Out Validation Set
K-Fold Validation
Iterated K-Fold Validation with Shuffling
Setting a benchmark
random.seed
The last; and often most overlooked part of the Data Science project methodology is about communicating the value you’ve just created in this project. So how does that look?
Delivering Results to Stakeholders
- Convey the message in business terms.
- Highlight the business impact and opportunity.
- Correctly call out the right call to action.
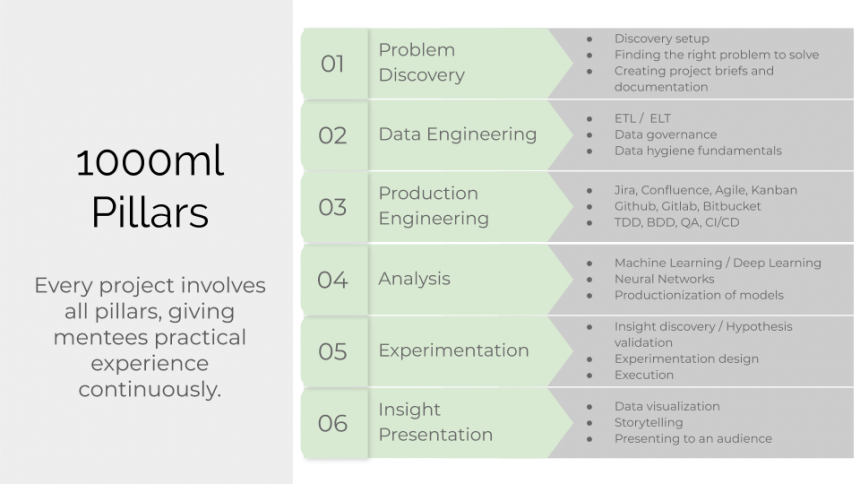
So what do you do when all signs point to having to go to University to gain any sort of advantage? Unfortunately it’s the current state of affairs that most employers will not hire you unless you have a degree for even junior or starting jobs. Once you have that degree, coming to a Finishing and Mentor Program, with 1000ml being the only one worldwide, is the only way forward to gaining the practical knowledge and experience that will jump start your career.
Check out our next dates below for our upcoming seminars, labs and programs, we’d love to have you there.