Gathering up the tools required for this job – we’ll need the table detector, something to extract the table data (lots of details here – borderless and bordered tables require different strategies) and the means to read out that elusive associated text.
I suggest jumping into Colab for all of your experimentation, that way you can make use of a GPU (big help on speed), unless you have your own, then you do you…
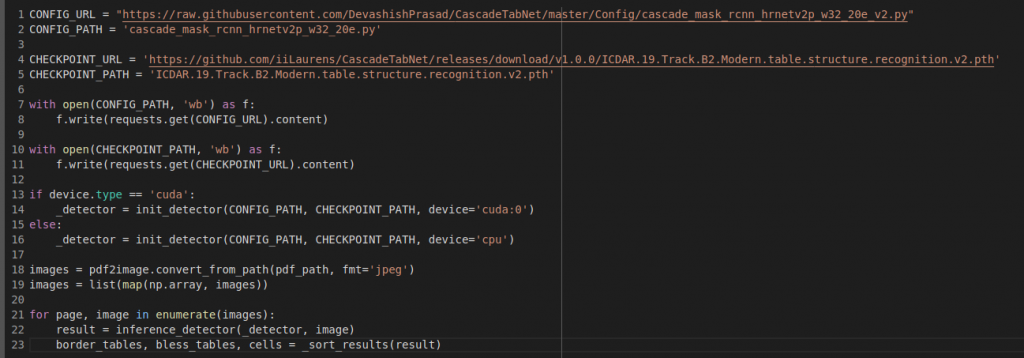
To start, we’ll pick our table detector(s). There’s more than a few out there for sure, since they are mostly just fine tuned image detectors. MMDetection in conjunction with MMCV will be used – they are both subsets of OpenMMLab, a library of image detection, recognition, classification and more. This library is very robust and quite good from my experience with it, albeit finicky, as with all computer vision software. It can be a little tricky to install the right versions of these tools, especially if you’re bringing it into an already hefty list of requirements. At the very least you’ll have to be somewhat specific with your version choice of PyTorch, CUDA and NumPy. Here’s a guide from the docs to get started.
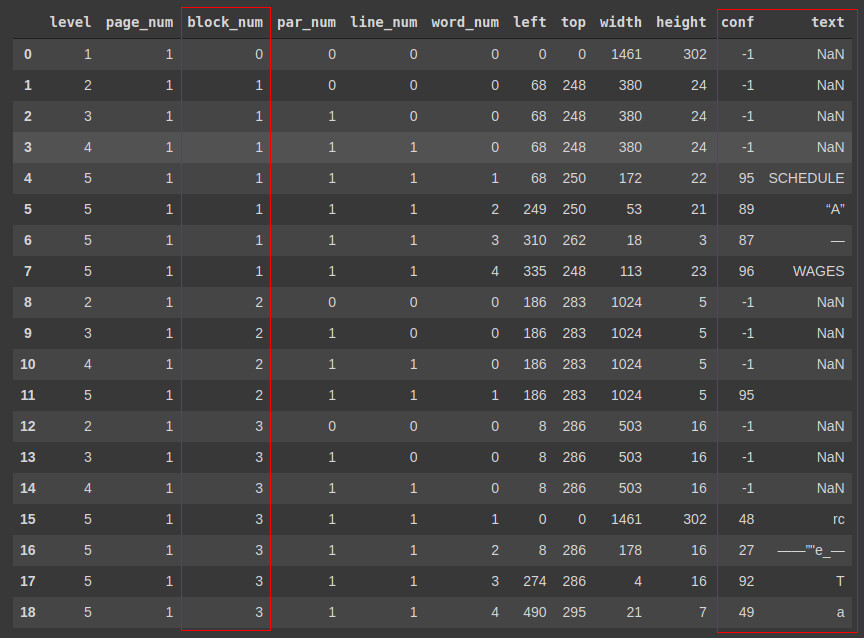
Next up of course we’ll need the usual CV2 (opencv-python), and PyTesseract. Don’t forget that you’ll need to install poppler-utils and tesseract-ocr to your system/Colab (not your environment, i.e. apt install …) for these to work.
Finally, we’ll need a library called Camelot. This one is particularly optimized for reading table contents, and technically can detect tables as well, but falls quite short of MMDet in this regard. Therefore, we can just feed Camelot the table locations and tell it to read them out.
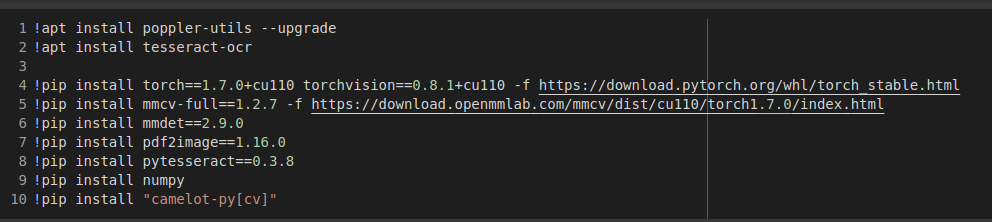
Here’s an image of the installed libraries and packages mentioned above (written in Colab). The versions used are not always the latest, as there were other dependencies to keep in mind, so these were just the ones I needed.