
By VICTOR ANJOS
An NLP platform must be ready to process text and analyze its content to find whatever distinct features a system wishes to read. Multiple components will help identify different text aspects in one’s work This will form the basis of NLP Technical Knowledge required going forward..
NLTK Library For Processing Purposes
A Natural Language Toolkit or NLTK library will be necessary for handling an NLP project. The NLTK setup can help a programmer manage various concepts in an NLP project, including:
- Stemmers that can produce variants of certain words
- Tokenizers that will split the content into words or sentences to make data more accessible to read
- Part of speech triggers that help identify what types of words appear in the content
- Lemmatization support for reviewing the inflections for a word, creating a dictionary-based definition of a term
- Named-entry recognition that identifies specific items and their orders
The NLTK library will help people create an NLP setup that helps identify unique concepts surrounding different words. The NLP system should be ready to divide text blocks, sentences, and even individual words into multiple portions that are easy for an NLP setup to read.

Data Visualization
The NLTK can review how often certain words appear at a time. A data visualization system is necessary for helping spot which words appear the most often or where they appear in a grouping of text. The system helps identify the content that is most important in the work process.
Machine Learning Support Via Supervision
A developer must be ready to handle machine learning programs to make an NLP setup ready. The machine learning can entail one of two concepts:
1. Supervision is necessary for most situations. In this system, the text the NLP program uses undergoes thorough analysis to produce labels for each item. The labels can include as many detailed signifiers and points on terms as necessary.
2. Unsupervised NLP support will not include labels. This system makes it easier for the NLP setup to learn things, but it may be hard for some programs to classify data.
When planned well, machine learning helps an NLP system find patterns without human involvement. The platform will learn from many experiences if the machine learning system undergoes proper tuning.
But to make it work, there should be some supervision involved to ensure the NLP setup can work on its own after a while. Data cleaning is necessary, as it clears out filler words and focuses on more specific terms that can define what someone is writing. Unique term lists are also critical for addressing content well enough.
Unsupervised learning can also work, as it includes reviewing content based on how close certain things are to one another or how words might connect. But developers must monitor the learning process well to determine what fits.
Feature Extraction
Feature extraction is a practice where an NLP system reviews content and analyzes its parts to identify the unique context of something.
The bag-of-words system is the most common feature extraction measure available. All unique words are analyzed based on how they appear in a sentence. A feature matrix will monitor different words and determine which ones appear in the same sentence, helping create an analysis of how certain words relate to each other.
The TF-IDF system can also work in the process. This option starts by analyzing the term frequency of something to see how many times a word appears in a feature. The system then reviews the inverse document frequency to see how often the word occurs throughout an entire set, analyzing how rare the word is versus others.
Sentiment Analysis
NLP setups are more efficient when they recognize the sentiment someone has when entering content. A person might have a sentiment showing frustration, or perhaps that person has a genuine question one wishes to ask.
Sentiment analysis is a critical technical part of the NLP process for all to follow. A recursive neural network or RvNN can appear in the NLP system to identify the sentiment that a writer holds, including:
- Adjectives and other signifiers that suggest a person is feeling some way
- The tone of the writing, including how rushed someone might be or if that person is relaxed
- Any essential words surrounding what one thinks about a product or service
- The frequency of certain words appearing somewhere
The RvNN will review the hierarchy of each word that appears in a sentence, calculating what sentiments and concepts each word represents. The ranking includes a review of how each word ranks and what connects with each other. The analysis is necessary for producing a more thorough review of what’s open.
Topic Modeling
The last part of an NLP project to review involves topic modeling, a practice where an NLP setup gathers unique themes from the content it reviews. A modeling process can include one of these options for figuring out the content that appears somewhere:
- Latent dirichlet allocation reviews the possible topics that may appear in the content.
- Latent semantic analysis reviews the singular values of each word that appears at a time, helping find the semantics for the content.
- Probabilistic latent semantic analysis covers the probability of whether certain words may occur together. The words that the NLP system determines are the most similar and likely to appear together are the focal point of this setup.
How Long Does It Take To Complete a Project?
The timing for getting these features ready for an NLP project will vary, but people can expect to spend at least three months getting it all prepared for use. The timing is necessary for helping configure the NLP system and note how well it works.
Proper planning is necessary for establishing a thorough NLP project. The best work can make it easier for an NLP system to review data and make connections while producing the ideal responses to everything in a setup.
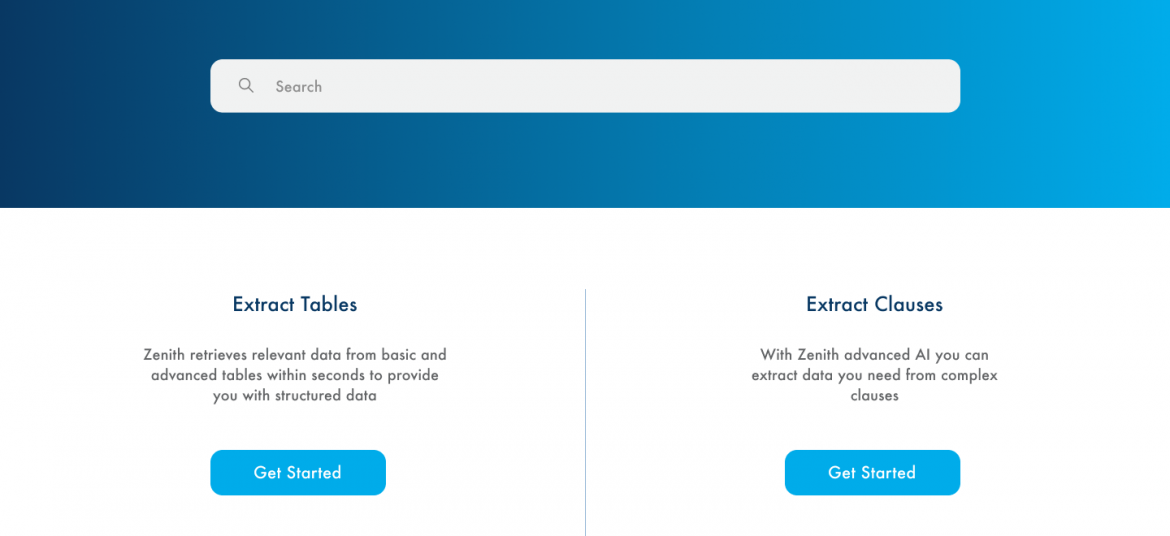
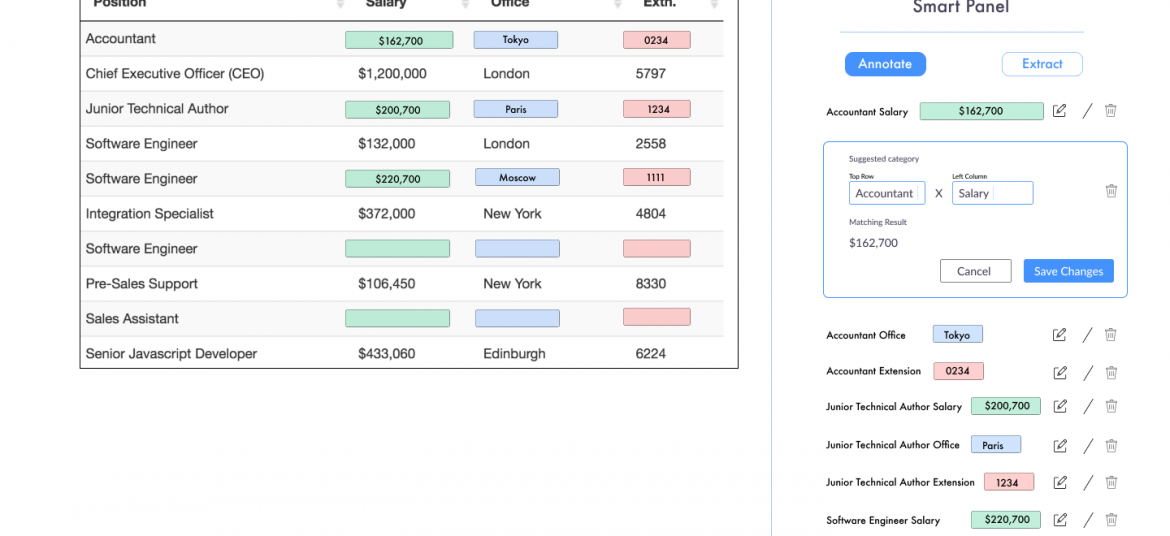

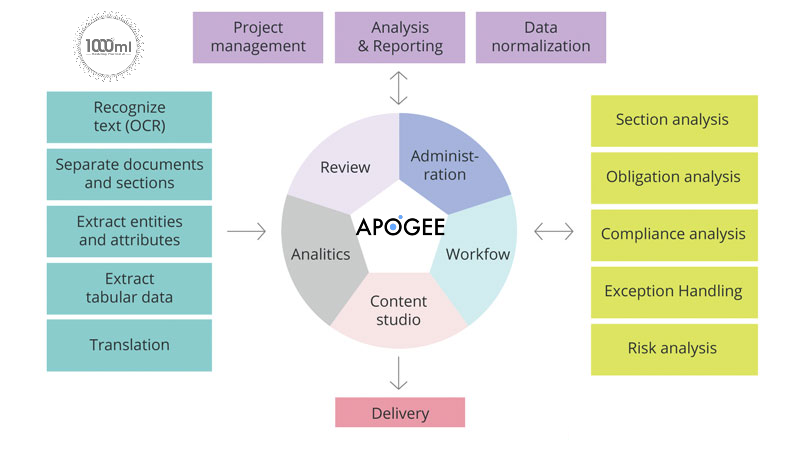
Apogee Suite of NLP and AI tools made by 1000ml has helped Small and Medium Businesses in several industries, large Enterprises and Government Ministries gain an understanding of the Intelligence that exists within their documents, contracts, and generally, any content.
Our toolset – Apogee, Zenith and Mensa work together to allow for:
- Any document, contract and/or content ingested and understood
- Document (Type) Classification
- Content Summarization
- Metadata (or text) Extraction
- Table (and embedded text) Extraction
- Conversational AI (chatbot)
Search, Javascript SDK and API
- Document Intelligence
- Intelligent Document Processing
- ERP NLP Data Augmentation
- Judicial Case Prediction Engine
- Digital Navigation AI
- No-configuration FAQ Bots
- and many more
Check out our next webinar dates below to find out how 1000ml’s tool works with your organization’s systems to create opportunities for Robotic Process Automation (RPA) and automatic, self-learning data pipelines.

{kind=link}
Comments are closed.