By VICTOR ANJOS
Introduction
The problem of understanding written language is a difficult one, and it’s getting more challenging as we use the internet to communicate in increasingly complex ways. But even though this problem seems hard at first glance, most people actually agree on what language is: it’s just words strung together with spaces between them. So why would it be so hard for computers? Well, there are two main reasons:
How computers understand written text
• Text to number transformation
• Bag of words model
• Vector space model
These three things are the foundation of how computers understand written text. Each one is a different approach that can be applied to natural language understanding (NLU), which is the process of getting computers to understand human language and communicate with humans in that language.
Computers need to convert text into something they can understand.
In order to understand written text, computers must be able to convert words into numbers. There are two main methods of doing this:
• The text-to-number transformation is the process by which a computer converts a piece of writing into numerical values that represent its content. These values can then be used by algorithms to train the machine on what concepts are present in the text and how they relate to each other.
• The bag of words model is an approach used for information retrieval and natural language processing that involves counting word frequency counts in documents or other strings, but does not use probability distribution models such as Bayesian networks.
NLP allows computers to actually “understand” text so that they can process it in a useful way.
NLP allows computers to actually “understand” text so that they can process it in a useful way. This is done by converting the text into numbers, which are easier for computers to understand. The following example shows how this can be done:
It’s raining cats and dogs outside! (text)
This sentence has 11 words: 5 nouns, 3 verbs and 3 adjectives. We can use NLP to convert this sentence into numbers:
5 + 3 + 2 = 10 (number of words)
11 / 5 = 2.2 (average number of syllables per word)
2 + 1 + 2 = 5 (number of characters per word)
This means that it would take approximately five times longer than usual for someone who doesn’t know English as their native language to learn how read/write in English if we were using computer programs that only understand written language at its most basic level instead of being able to interpret words based on their meaning through context clues like these examples above where we were able without knowing what those words meant beforehand!
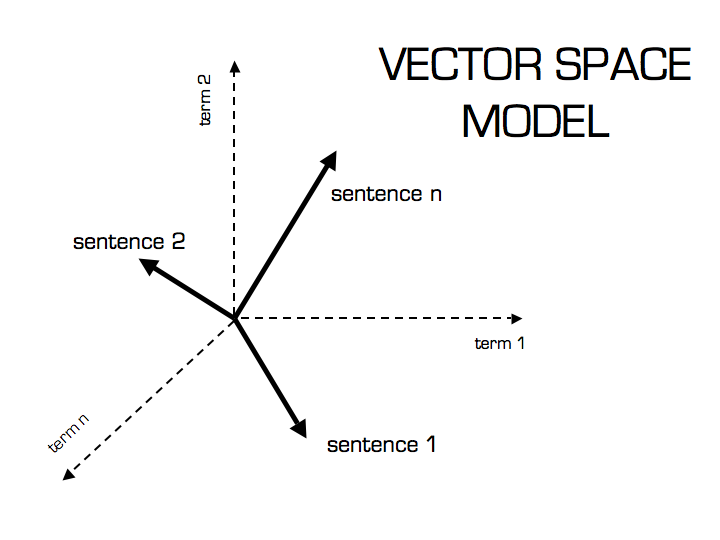
The most common historical method is called a bag of words model, or a vector space model
The most common historical method is called a bag of words model, or a vector space model. A vector space model represents each document with a vector (i.e., a list of numbers). Each number in the vector represents some aspect of the document: for example, how long it is or whether it contains certain keywords. The algorithm then learns to predict which documents contain certain keywords by looking at which vectors are closest to each other.
This method has two key differences from what we’ll learn here:
• Vectors are not limited to binary values (such as “does this document contain keyword X?”) but rather can take on any real value between 0 and 1 – allowing us to use them as continuous values instead of as boolean flags; and
• For any given word w in our vocabulary V (the set of all possible words), we don’t just add one number corresponding to whether or not w appears in a given sentence; rather, we assign an entire vector whose elements represent our confidence level that w appears somewhere in S.
There are many variations of this approach, but generally speaking it makes heavy use of statistics to find commonalities between documents and interpret each word’s meaning based on other similar documents.
When it comes to understanding what’s written in a document, there are many approaches that we can take. We could look at the raw data itself and try to determine patterns by hand. Or we could use statistical methods to help us learn those patterns automatically.
Both of these techniques have their merits; however, statistical methods generally involve less work upfront and produce better results than manual ones. In this article, I’ll discuss how statistical methods are used in natural language processing (NLP) and how they differ from other approaches like machine learning or deep learning.
NLU is the task of computers understanding human language.
NLU is the task of computers understanding human language. It encompasses many different subfields that focus on different aspects of natural language processing. NLU is a subset of NLP, which aims at enabling computers to process and generate text in a way that mimics what humans would do.
NLU is not just about understanding text, but also understanding speech. As we’ve seen in previous posts (1), there are several ways to represent natural language including plain text as well as deep neural networks that can generate sentences from scratch using recurrent neural networks (RNNs).
The computer analyzes grammar
The computer needs to know the structure of language, otherwise it won’t be able to make sense of anything. In order to determine the meaning of a sentence, the computer must first understand its syntax. Syntax is the way in which words are combined into phrases and clauses, which in turn form sentences. If a sentence doesn’t have proper syntax (e.g., when one or more words are missing), then it can’t be understood by the computer and won’t have any meaning for it either.
The computer adds context to words
- The computer understands the meaning of words in context.
- The computer understands the meaning of words based on their context.
- The computer understands the meaning of words based on the context in which they are used.
- The computer understands the meaning of words based on the context in which they are found.
The computer uses a word as a proxy for other words
Word2vec is an algorithm that helps computers to understand written text. It uses neural networks, deep learning and other techniques to turn words into vectors instead of just numbers. You can think of this as the same way you would think of a person’s name as a proxy for their identity: John Smith = 1, Jane Doe = 2, etc.. This allows computers to make sense out of sentences with many different nouns and verbs and understand what they mean individually in context with each other.
Using these word vectors allows us to do things like sentiment analysis (classifying whether a sentence contains positive or negative sentiment), text classification (classifying whether something is an article about sports), text clustering (grouping related news articles together) and more!
Conclusion
In short, NLU is a fancy way of saying “computers understand written language.” The most common technique for doing this is called a bag of words model. This approach uses statistics to find commonalities between documents and interpret each word’s meaning based on other similar documents. There are many variations on this general theme that have been developed over time, but they all follow the same basic principles: use statistics to find patterns in language so that computers can make decisions based on those patterns.
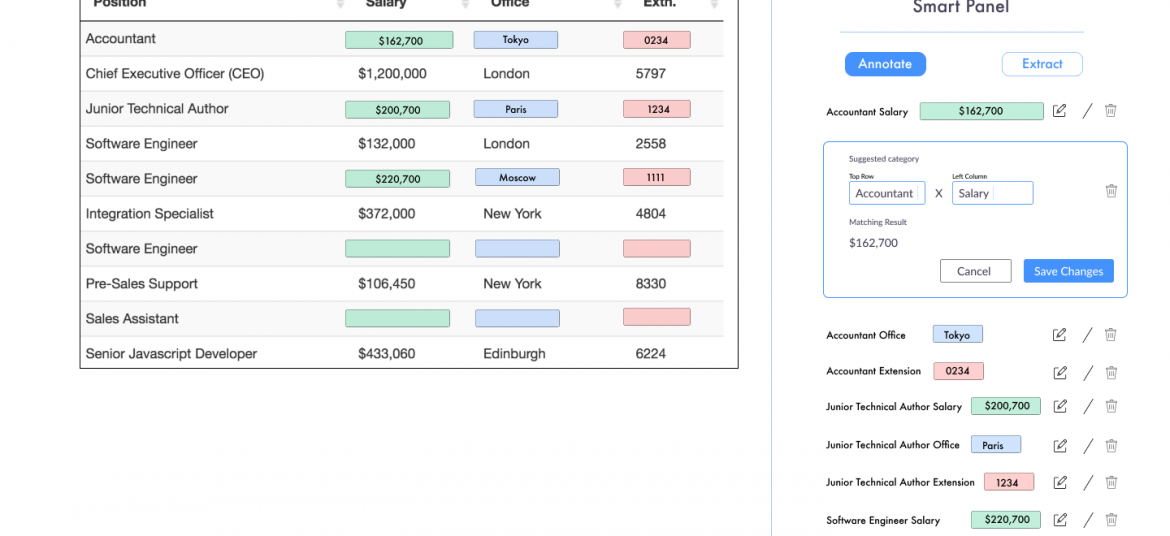

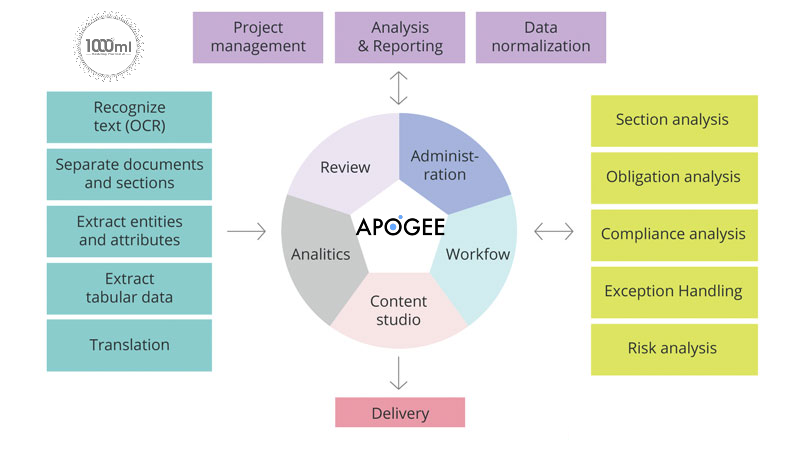
Apogee Suite of NLP and AI tools made by 1000ml has helped Small and Medium Businesses in several industries, large Enterprises and Government Ministries gain an understanding of the Intelligence that exists within their documents, contracts, and generally, any content.
Our toolset – Apogee, Zenith and Mensa work together to allow for:
- Any document, contract and/or content ingested and understood
- Document (Type) Classification
- Content Summarization
- Metadata (or text) Extraction
- Table (and embedded text) Extraction
- Conversational AI (chatbot)
Search, Javascript SDK and API
- Document Intelligence
- Intelligent Document Processing
- ERP NLP Data Augmentation
- Judicial Case Prediction Engine
- Digital Navigation AI
- No-configuration FAQ Bots
- and many more
Check out our next webinar dates below to find out how 1000ml’s tool works with your organization’s systems to create opportunities for Robotic Process Automation (RPA) and automatic, self-learning data pipelines.